GPU Cluster Alpha Centauri¶
Overview¶
The multi-GPU cluster Alpha Centauri has been installed for AI-related computations (ScaDS.AI).
Hardware Details¶
A brief overview of the hardware specification is documented on the page HPC Resources.
Processor
- 2 x AMD EPYC 7352 (24 cores) @ 2.3 GHz (Datasheet)
- Configured with 4 NUMA domains, 2 on each socket
Graphics Processing Unit
- 8 x Nvidia A100 GPUs (Whitepaper)
- Memory: 40 GiB HBM2, 1555 GB/s theoretical peak bandwidth
- Interfaces: SXM4 package, PCIe 4.0 x16, interconnected via 12 x NVLink
- Power limit: 400 W
System Memory
All Alpha Centauri nodes feature 1 TiB of RAM.
- 2 sockets with 8 memory channels each
- 2 x 32 GiB DDR4-3200 (configured: 2933 MT/s) S4ECD4ED ECC-RDIMMs per channel, 32 DIMMs total (Part No. M393A4K40DB3-CWE, product page)
- Theoretical peak bandwidth across both sockets: 375.4 GB/s
Local Storage
Alpha Centauri has two local SSDs, one 240 GB 2.5" SATA SSD, and one 3.84 TB U.2 SSD. The
former makes a 158.5 GiB partition available to users as an xfs in /var/tmp, while the
latter is completely available as an xfs at /tmp. The SATA SSD is an Intel SSD D3-S4510
(Part No. SSDSC2KB240G8, archived datasheet).
The U.2 SSD is a Samsung PM983 (Part No. MZQLB3T8HALS-00007, datasheet).
Both parts' specifications are listed in the table below.
| Disk Type | Usable Capacity | Sequential read/write | Random read/write | Mountpoint |
|---|---|---|---|---|
| NVMe SSD | 3.5 TiB | 3.2/2.0 GB/s | 540/55 kIOPS | /tmp |
| SATA SSD | 158.5 GiB | 560/510 MB/s | 97/36 kIOPS | /var/tmp |
See also: Node-Local Storage in Jobs
Networking
Alpha Centauri nodes feature two Mellanox ConnectX-6 InfiniBand devices (user manual)
for networking. Both network interfaces operate at 4xHDR (200 Gb/s, 25 GB/s), providing the
node with 400 Gb/s of network connectivity.
System Architecture
The system is based on Gigabyte G492-ZL0-00 servers. While the system's documentation has become unavailable, system architecture closely resembles that of the related G492-ZL2 server (product page, user manual):
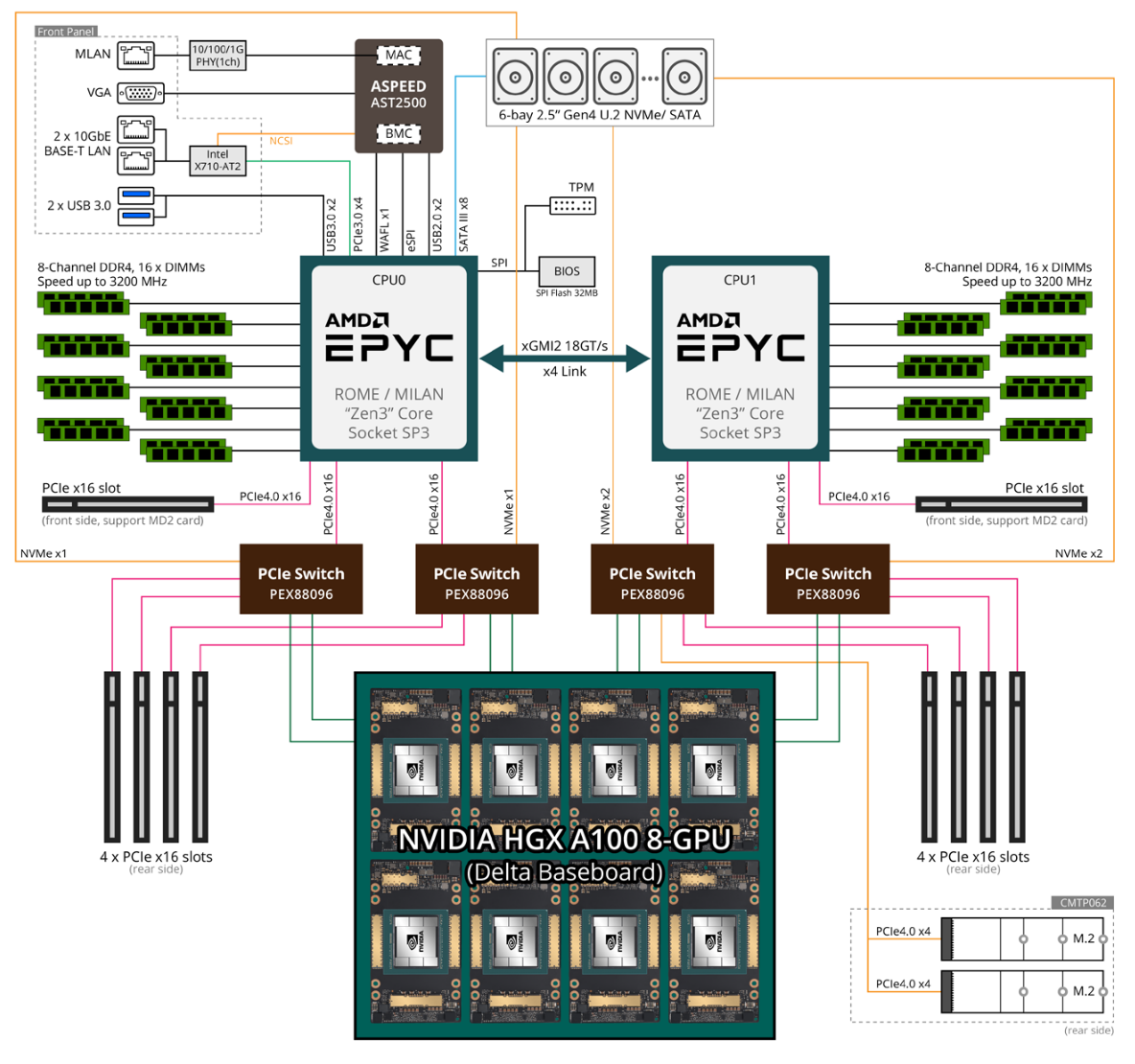
Architecture output of hwloc-ls:

Operating System
Alpha Centauri runs Rocky Linux version 9.6.
Filesystems¶
Since July 5th 2024, Alpha Centauri is fully integrated in the InfiniBand infrastructure of
Barnard. With that, all filesystems
(/home, /software, /data/horse, /data/walrus, etc.) are available.
Cluster-Specific Filesystem quokka¶
Similar to the filesystem
cat on Capella,
quokka is designed to meet the high I/O
requirements of AI and ML workflows. It is a Quobyte filesystem mounted under /data/quokka. It is
also available on Romeo for pre- and post-processing where no GPUs are required, as well as on the
Datamover and Dataport nodes
for data transfer.
quokka has only limited capacity, hence workspace duration is significantly shorter than
in other filesystems. We recommend that you only store actively used data there.
To transfer input and result data from and to the filesystems horse and walrus, respectively,
you will need to use the Datamover nodes. Regardless of the
direction of transfer, you should pack your data into archives (,e.g., using dttar command)
for the transfer.
Do not invoke data transfer to the filesystems horse and walrus from login nodes.
Both login nodes are part of the cluster. Failures, reboots and other work
might affect your data transfer resulting in data corruption.
Usage¶
Note
The NVIDIA A100 GPUs may only be used with CUDA 11 or later. Earlier versions do not recognize the new hardware properly. Make sure the software you are using is built with CUDA11.
There is a total of 48 physical cores in each node. SMT is also active, so in total, 96 logical
cores are available per node.
Each node on the cluster Alpha has 2x AMD EPYC CPUs, 8x NVIDIA
A100-SXM4 GPUs, 1 TB RAM and 3.5 TB local space (/tmp) on an NVMe device.
Note
Multithreading is disabled per default in a job. See the Slurm page on how to enable it.
Resource Limits¶
To enable a fair share of the resources, per-job resource limits are enforced. Please refer to the general resource limits table and the subsection QOS Resource Limits for further reference.
On Alpha Centauri additional limits apply to used CPUs and memory to ensure sufficient resources for GPU jobs. Refer to this table.
Modules¶
The easiest way is using the module system.
All software available from the module system has been specifically built for the cluster Alpha
i.e., with optimization for Zen2 microarchitecture and CUDA-support enabled.
To check the available modules for Alpha, use the command
marie@login.alpha$ module spider <module_name>
Example: Searching and loading PyTorch
For example, to check which PyTorch versions are available you can invoke
marie@login.alpha$ module spider PyTorch
-------------------------------------------------------------------------------------------------------------------------
PyTorch:
-------------------------------------------------------------------------------------------------------------------------
Description:
Tensors and Dynamic neural networks in Python with strong GPU acceleration. PyTorch is a deep learning framework
that puts Python first.
Versions:
PyTorch/1.12.0
PyTorch/1.12.1-CUDA-11.7.0
PyTorch/1.12.1
[...]
Not all modules can be loaded directly. Most modules are build with a certain compiler or toolchain that need to be loaded beforehand. Luckely, the module system can tell us, what we need to do for a specific module or software version
marie@login.alpha$ module spider PyTorch/1.12.1-CUDA-11.7.0
-------------------------------------------------------------------------------------------------------------------------
PyTorch: PyTorch/1.12.1-CUDA-11.7.0
-------------------------------------------------------------------------------------------------------------------------
Description:
Tensors and Dynamic neural networks in Python with strong GPU acceleration. PyTorch is a deep learning framework
that puts Python first.
You will need to load all module(s) on any one of the lines below before the "PyTorch/1.12.1" module is available to load.
release/23.04 GCC/11.3.0 OpenMPI/4.1.4
[...]
Finaly, the commandline to load the PyTorch/1.12.1-CUDA-11.7.0 module is
marie@login.alpha$ module load release/23.04 GCC/11.3.0 OpenMPI/4.1.4 PyTorch/1.12.1-CUDA-11.7.0
Module GCC/11.3.0, OpenMPI/4.1.4, PyTorch/1.12.1-CUDA-11.7.0 and 64 dependencies loaded.
Now, you can verify with the following command that the pytorch module is available
marie@login.alpha$ python -c "import torch; print(torch.__version__); print(torch.cuda.is_available())"
1.12.1
True
Python Virtual Environments¶
Virtual environments allow you to install
additional Python packages and create an isolated runtime environment. We recommend using
virtualenv for this purpose.
Hint
We recommend to use workspaces for your virtual environments.
Example: Creating a virtual environment and installing torchvision package
As a first step, you should allocate a workspace
marie@login.alpha$ srun --nodes=1 --cpus-per-task=1 --gres=gpu:1 --time=01:00:00 --pty bash -l
marie@alpha$ ws_allocate --name python_virtual_environment --duration 1
Info: creating workspace.
/horse/ws/marie-python_virtual_environment
remaining extensions : 2
remaining time in days: 1
Now, you can load the desired modules and create a virtual environment within the allocated workspace.
marie@alpha$ module load release/23.04 GCCcore/11.3.0 GCC/11.3.0 OpenMPI/4.1.4 Python/3.10.4
Module GCC/11.3.0, OpenMPI/4.1.4, Python/3.10.4 and 21 dependencies loaded.
marie@alpha$ module load PyTorch/1.12.1-CUDA-11.7.0
Module PyTorch/1.12.1-CUDA-11.7.0 and 42 dependencies loaded.
marie@alpha$ which python
/software/rome/r23.04/Python/3.10.4-GCCcore-11.3.0/bin/python
marie@alpha$ pip list
[...]
marie@alpha$ virtualenv --system-site-packages /data/horse/ws/marie-python_virtual_environment/my-torch-env
created virtual environment CPython3.8.6.final.0-64 in 42960ms
creator CPython3Posix(dest=/horse/.global1/ws/marie-python_virtual_environment/my-torch-env, clear=False, global=True)
seeder FromAppData(download=False, pip=bundle, setuptools=bundle, wheel=bundle, via=copy, app_data_dir=~/.local/share/virtualenv)
added seed packages: pip==21.1.3, setuptools==57.2.0, wheel==0.36.2
activators BashActivator,CShellActivator,FishActivator,PowerShellActivator,PythonActivator,XonshActivator
marie@alpha$ source /data/horse/ws/marie-python_virtual_environment/my-torch-env/bin/activate
(my-torch-env) marie@alpha$ pip install torchvision==0.13.1
[...]
Installing collected packages: torchvision
Successfully installed torchvision-0.13.1
[...]
(my-torch-env) marie@alpha$ python -c "import torchvision; print(torchvision.__version__)"
0.13.1+cu102
(my-torch-env) marie@alpha$ deactivate
JupyterHub¶
JupyterHub can be used to run Jupyter notebooks on Alpha Centauri cluster. You can either use the standard profiles for Alpha or use the advanced form and define the resources for your JupyterHub job. The "Alpha GPU (NVIDIA Ampere A100)" preset is a good starting configuration.
Containers¶
Singularity containers enable users to have full control of their software environment. For more information, see the Singularity container details.
Nvidia NGC containers can be used as an effective solution for machine learning related tasks. (Downloading containers requires registration). Nvidia-prepared containers with software solutions for specific scientific problems can simplify the deployment of deep learning workloads on HPC. NGC containers have shown consistent performance compared to directly run code.
Partition alpha-interactive¶
The partition alpha-interactive can be used for your small tests and compilation of software.
In addition, JupyterHub instances that require low GPU utilization or
only use GPUs for a short period of time in their allocation are intended to use this partition.
You need to add #SBATCH --partition=alpha-interactive to your job file and
--partition=alpha-interactive to your sbatch, srun and salloc command line, respectively,
to address this partition.
The partition alpha-interactive is configured to use MIG
configuration of 1/7.
Resource limits and interactive job allocation
The interactive partition uses the login nodes. In order to keep them working while still allowing interactive usage with access to GPUs only 1 GPU, 1 CPU and 20 GB of RAM can be allocated on this partition. So you can use the following command to get a shell with GPU access in an interactive job:
marie@login.alpha$ srun --pty --partition=alpha-interactive --ntasks=1 --nodes=1 --time=1:0:0 --cpus-per-task=1 --threads-per-core=2 --mem=20G --gres=gpu:1 bash`
Backlinks¶
The following pages link to this page: