Data Life Cycle Management¶
Correct organization of the structure of an HPC project is a straightforward way to the efficient work of the whole team. There have to be rules and regulations that every member should follow. The uniformity of the project can be achieved by taking into account and setting up correctly
- the same set of software (modules, compiler, packages, libraries, etc),
- a defined data life cycle management including the same data storage or set of them,
- and access rights to project data.
The used set of software within an HPC project can be managed with environments on different levels either defined by modules, containers or by Python virtual environments. In the following, a brief overview on relevant topics w.r.t. data life cycle management is provided.
Data Storage and Management¶
In general, you should separate your data and store it on the appropriate storage and filesystem. What is the appropriate storage and filesystem depends on the amount/volume of data and its kind, and might differ over time. Please note the following rules of thumb:
- Use your personal
/homedirectory for the limited amount of personal data, e.g., simple examples and the results of calculations. Your/homedirectory is not a working directory! However,/homefilesystem is backed up. The section Global/homeFilesystem provides additional information. - Use your
/projectdirectory for project-related data. This directory enables collaboration by sharing data with colleagues and project members. Please refer to the section Global/projectsFilesystem for further information. - Use
workspacesas a place for your working data (i.e. data sets). Recommendations of choosing the most suitable filesystem for your workspaces is presented on the page Working Filesystems. - Use the Intermediate Archive and the Long-Term Archive to store all kind of data that needs to be kept for a long time, e.g. result data.
Backup¶
The backup is a crucial part of any project. Organize it at the beginning of the project. The
backup mechanism on ZIH systems covers only the filesystems /home and /projects. The section
Backup holds additional information.
Warning
If you accidentally delete your data in the "no backup" filesystems it can not be restored!
Folder Structure and Organizing Data¶
Organizing of living data using the filesystem helps for consistency of the project. We recommend following the rules for your work regarding:
- Organizing the data: Never change the original data; Automatize the organizing the data; Clearly separate intermediate and final output in the filenames; Carry identifier and original name along in your analysis pipeline; Make outputs clearly identifiable; Document your analysis steps.
- Naming Data: Keep short, but meaningful names; Keep standard file endings; File names don’t replace documentation and metadata; Use standards of your discipline; Make rules for your project, document and keep them (See the README recommendations below)
This is the example of an organization (hierarchical) for the folder structure. Use it as a visual illustration of the above:
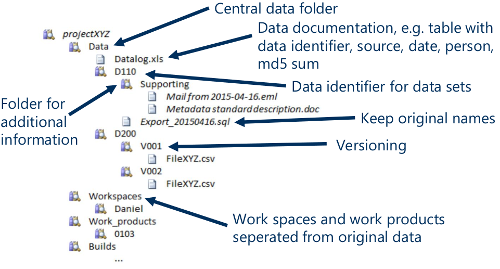
Keep in mind the input-process-output pattern for the folder structure within your projects.
README Recommendation¶
In general, a README file provides a brief and general
information on the software or project. A README file is used to explain the purpose of the
project and the structure of the project in a short way. We recommend providing a README file
for entire project as well as for every important folder in the project.
Example of the structure for the README: Think first: What is calculated why? (Description); What is expected? (software and version)
README
Title:
User:
Date:
Description:
Software:
Version:
Repo URL:
Metadata¶
Another important aspect is the Metadata. It is sufficient to use Metadata for your HPC project. Metadata standards, i.e., Dublin core, OME, will help to do it easier.
Data Hygiene¶
Don't forget about data hygiene: Classify your current data into critical (need it now), necessary (need it later) or unnecessary (redundant, trivial or obsolete); Track and classify data throughout its life cycle (from creation, storage and use to sharing, archiving and destruction); Erase the data you don’t need throughout its life cycle.
Access Rights¶
The concept of permissions and ownership is crucial in Linux. See the
slides of HPC introduction for understanding of the main concept.
Standard Linux changing permission command (i.e chmod) valid for ZIH systems as well. The
group access level contains members of your project group. Be careful with 'write' permission
and never allow to change the original data.
Backlinks¶
The following pages link to this page: